Land Cover Classification
Training-free material & context mapping
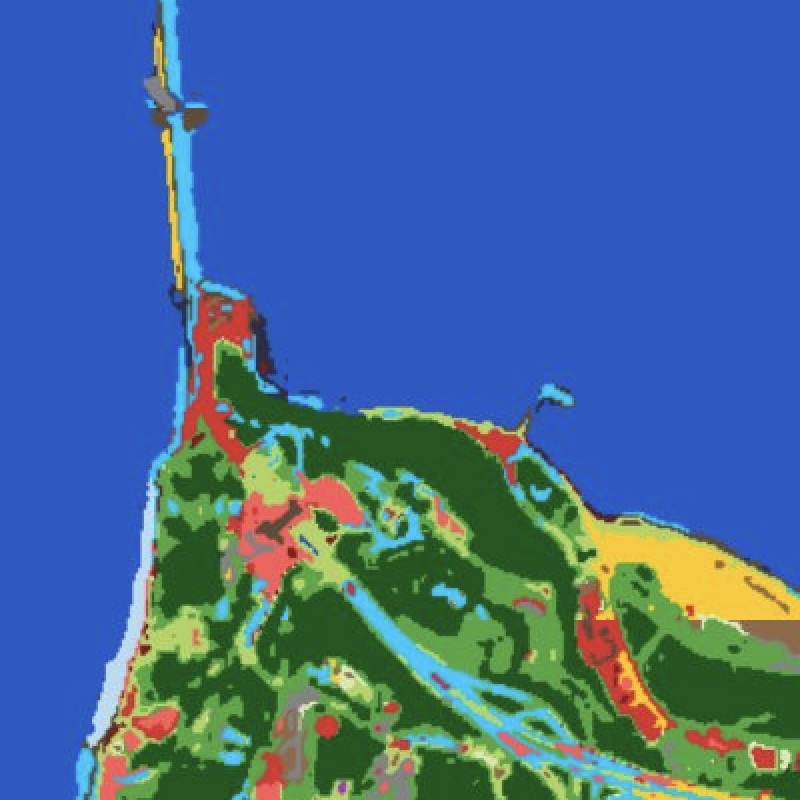
Most land-cover products are supervised classifiers: they need labelled training data, encode brittle correlations, and fail to generalise across geographies. EarthToDate takes the opposite approach — a physics-based, training-free pipeline that discovers surface materials directly from the multispectral signal and describes a scene rather than forcing it into a fixed set of classes.
Two independent layers compose into every answer. The first clusters each pixel by spectral material identity — concrete, asphalt, metal roof, water, soil, vegetation — in an illumination-decoupled colour space, with cloud and shadow falling out as their own classes for free. The second characterises each pixel's spatial context: how diverse, how textured, and how large the surrounding patch is. Built-up, roads, agriculture, solar farms, quarries and isolated structures then emerge as queries against this representation, not as separately-trained models.
Because the method encodes material physics and the structural signature of human-built environments — both invariant across geography — it runs anywhere on Earth with no local calibration: on full Sentinel-2 multispectral, on RGB basemaps, or on enhanced derived-resolution imagery alike. Default semantic labels come from OpenStreetMap as a majority vote, never as ground truth, so the map stays current and high-confidence disagreements with OSM surface as candidate change events rather than errors.
The same representation is the foundation beneath ETD's construction detection, corridor monitoring and agricultural products: every built-up, road, cropland or water query in the platform reads from one consistent, interpretable land-cover layer.
Frequently asked questions
What is Land Cover Classification?
Most land-cover products are supervised classifiers: they need labelled training data, encode brittle correlations, and fail to generalise across geographies. EarthToDate takes the opposite approach — a physics-based, training-free pipeline that discovers surface materials directly from the multispectral signal and describes a scene rather than forcing it into a fixed set of classes.
What data and resolution does Land Cover Classification use?
Physics-based land-cover and built-up mapping with no training data and no proprietary labels — built-up, roads, cropland, water and more from one representation. (Training-free material & context mapping)
How does Land Cover Classification compare to the alternatives?
Two independent layers compose into every answer. The first clusters each pixel by spectral material identity — concrete, asphalt, metal roof, water, soil, vegetation — in an illumination-decoupled colour space, with cloud and shadow falling out as their own classes for free. The second characterises each pixel's spatial context: how diverse, how textured, and how large the surrounding patch is. Built-up, roads, agriculture, solar farms, quarries and isolated structures then emerge as queries against this representation, not as separately-trained models.